Last October, I published a call on this website for participation and feedback regarding a nonstandard book on data modeling and database design that I am working on. One of its nonstandard aspects is what I informally call a Lexicon of Lethal Database Designs: real-world design errors that have resulted in derailed—or even failed—IT projects, or in IT systems with serious maintenance problems.
Over the years—decades, actually—I have seen quite a few cases that deserve to be recorded to train students and warn (young) IT professionals. As a test, I have tried my hand at a case description of one of these; you can read it below.
I would appreciate reactions from fellow experts on this first attempt. I would also greatly appreciate other interesting cases you have encountered in your career. As mentioned, I intend to integrate these into the book I am working on, but they might also warrant a separate publication.
For now, I hope you enjoy this first lethal design case.
Best regards,
René Veldwijk
PS This case is about normalization, which is so basic that everyone can do it. For that reason, I chose not to describe the solution to the badly designed genealogy database model.
Deadly Database Designs
Case 1: Normalization — Can You Still Fail At It?
In this first case of deadly database designs, we go back to the 1970s and 1980s, the prehistory of database design, a time when blunders were made that your colleagues would never make again … or so you think.
Sometime in the late 1980s, as a junior information analyst for an international corporation, I was asked to design a system for generating their consolidated financial statements. Consolidation means combining the financial statements of companies in a group into a single whole. And that is more than simple addition.
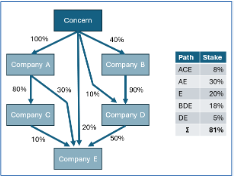
The group consisted of about 250 companies in a complex ownership structure. But not all subsidiaries were fully owned by the group. Simply put: one hundred euros in profit from a subsidiary of which you own 51 percent means 51 euros of profit for you. The remainder belongs to shareholders outside the group.
The accompanying figure gives a fairly realistic impression of the complexity. The group holds an 81% interest in subsidiary E: follow all paths between the group and E, multiply the percentages along each path, and sum the results. Not very difficult. At university I had learned normalization and ended up with two tables.
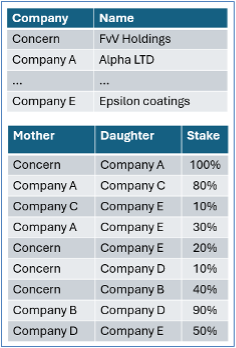
The head of accounting saw things differently. The new system was to replace software built 17 years earlier under his supervision, and correctly calculating the percentages had been an absolute horror story. To him, this was clearly a case of overconfidence by an inexperienced youngster.
In the end, I asked for and received permission to go home early to write a program on my IBM Model 30 PC using dBASE III. The following day, the head of accounting personally entered the most complex structure and was delighted when he saw the correct percentage. But now I wanted to know why it had previously turned into such a disaster.
A glance at the existing company file was enough:
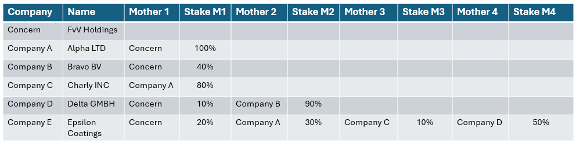
Determining an ownership percentage is now far more difficult. But remember that this design dated from the mid-1970s. Not only was the concept of “normalization” still unknown, it was also the era of tape files. It was common and often rational to cram data into as few files as possible. That logic only disappeared with the advent of direct-access storage and relational databases and theory. I could forgive them.
Normalization — Anyone Can Do That, Right?
Since the late 1970s, everyone has known that cramming too many kinds of data into too few tables leads to more complex software. Since the 1980s at least, everyone has known that a table should not contain repeating groups. By separating them into a separate table, technical limitations (“maximum four parent companies”) disappear and software becomes simpler, sometimes much simpler. Surely no one still creates designs like this, right?
The answer is: yes, but hesitatingly. There are lazy designers or designers dealing with old, poorly designed and/or documented systems for whom extending an existing table is the path of least resistance. But more interesting is a mistaken idea of what normalization actually is and the human inability to abstract adequately. I will give an example of both.
The Normalization Fallacy
During my time as a computer science lecturer, a student came up with the following design for a table containing data about breast cancer examinations:

This design may not be deadly, but it is unnecessarily expensive. We are storing the same kind of data for two breasts. The student had read that a repeating group referred to an indeterminate number of repetitions, and a woman naturally has two. He sensed that this was a bad design but was misled by the odd normalization rule.
It is not the number of repetitions that matters. Any repetition is unwanted. A good database design is characterized by not storing the same kind of data in multiple places if we can avoid it (which is not always the case). A left breast is the same kind of object as a right breast, and the same applies to the data elements describing the examination results of both. And with that, we arrive at the core of competent database design: finding the correct level of abstraction.
A Final Challenge: Test Your Colleagues!
As a final challenge, we present a simple case. We want a small database containing all descendants of Queen Wilhelmina of The Netherlands with her husband Prince Hendrik (thus excluding Hendrik’s illegitimate children). In total, this concerns 46 individuals, including Wilhelmina and Hendrik themselves.
Someone who can normalize but does not truly understand what good database design looks like may come up with this:
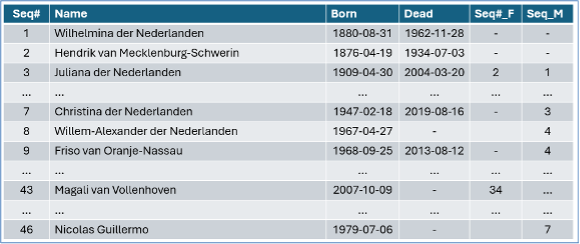
Test yourself and your colleagues. How did we go back to the 1970s again? If you see it, improving this design is a piece of cake if you know how to normalize data.
More technical information about the discussed cases and implementation scripts can be found here (link will be here soon). The correct design for the genealogy database is left to the reader, and the deeper logic behind all this awaits a book that is currently in development.
As for this genealogy challenge, the litmus test for better variants includes queries such as: “Which descendants of Wilhelmina are related to Magali van Vollenhoven in the 1st, 2nd, … nth degree?” Do try it on the design above and on your improvements. Enjoy!
Next episode: Generalization/Specialization — The Design That Is Always Wrong